

目次
始めに
こんにちは。AIシステム技術部 K山です。
前回は、予測の手法である「重回帰分析」を紹介しました。
前回のおさらい
| ・重回帰分析は、まだ起こっていない事象のデータを予測するとともに、予測結果に関係がある要因(説明変数)を調べることができる ・説明変数が多いと、その分データが必要にある上分かりにくいため、説明変数を絞る必要がある ・係数の値の大きさによって、どの説明変数が1番結果に影響を与えているかが分かる |
第5回のブログで紹介する予定だった「主成分分析」ですが、
その際は、手法が難しかったため断念しました。
今回は統計学の最後のブログになるので、もう一度取り組みたいと思います。
まずは、要約について改めて確認しましょう。
要約とは
要約ときくと、特徴を捉えてわかりやすくまとめるようなイメージですね。
統計では、値を使って特徴を捉える、ということになります。
分かりやすいものだと、「平均」が挙げられますが、そのほかにも、「最頻値」「中央値」というものがあります。
最頻値は、最も多い値、データが集中している値のことで、
中央値に関して第2回目のブログでも少し記載しましたが、
データを小さい順に並べたときにちょうど真ん中に来る値のことです。
平均値と中央値の違いがいまいちわかりにくい・・・
という方のために、ご説明いたします。
例えば、以下3つのデータがあるとします。
2 3 5 7 10
こちらの平均値・中央値をそれぞれ比べてみましょう。
平均値:(2+3+5+7+10)÷5=5.4
中央値:5
確かに違いますよね。
例を出して考えてみるとわかりやすいです。
今回は値が異なりましたが、場合によっては平均値と中央値が一致することもあります。
主成分分析とは
たくさんのデータから、できる限り情報を損なわない状態で縮小しそれを指標にすることです。
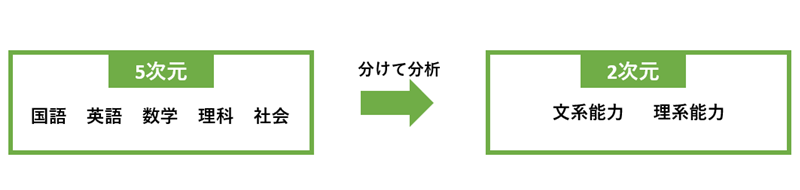
わかりやすい例でいうと、
以下のように、5科目のテスト結果を1つや2つのカテゴリでまとめ、数値を算出することも主成分分析の1つだそうです。

ほかにも、マーケティングでも使われることが多いようです。
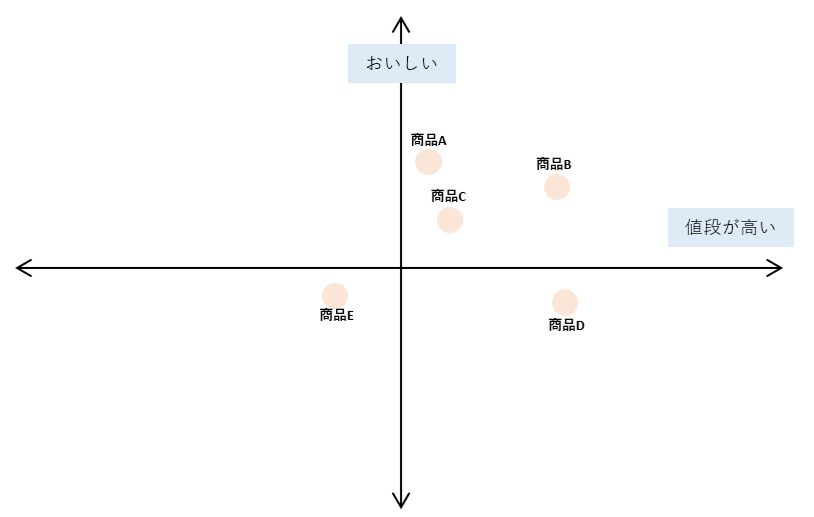
例えば、消費者アンケートを使い、商品の味の感想を集めます。
分析を行うと、結果が数値で算出されますが、
それではわかりにくいので、それぞれの特徴を可視化するために、以下のような指標図をつくることもあるようです。
主成分分析の手順
それでは、実際に主成分分析をしてみましょう!
ただ分析して数値を出すだけでなく、目に見えてわかりやすいポジショニングマップまでを作ってみたいです。
早速、サンプルデータを作ってみました。
こちらは、商品AからEまでの味を消費者へアンケートした結果になります。
こちらを使用して分析をしてみましょう。

このデータを基準化していきます。
キーワード
こうすることで、統計の妥当性と信頼性が確保される。
まずは、平均値と標準偏差を算出しましょう。
→標準偏差は、第3回目のブログで紹介しているため参考にどうぞ。
基準化した結果はこちらになります。

次に、相関係数を算出しましょう。
キーワード
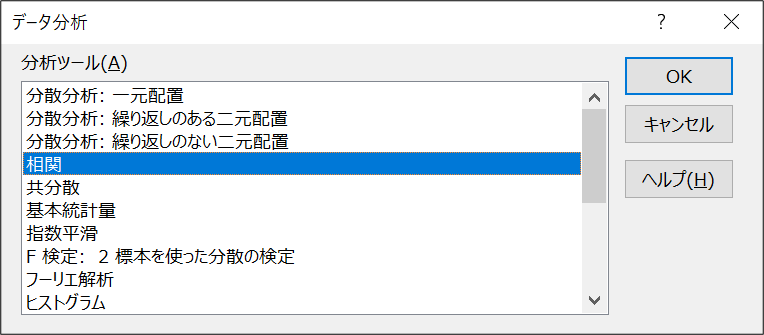
Excelのデータ分析ツールを使うと、簡単に結果が出るようです。
「データ」タブの「データ分析」ボタンを押下すると以下のようなポップアップが出てくるので、「相関」を選択しましょう。
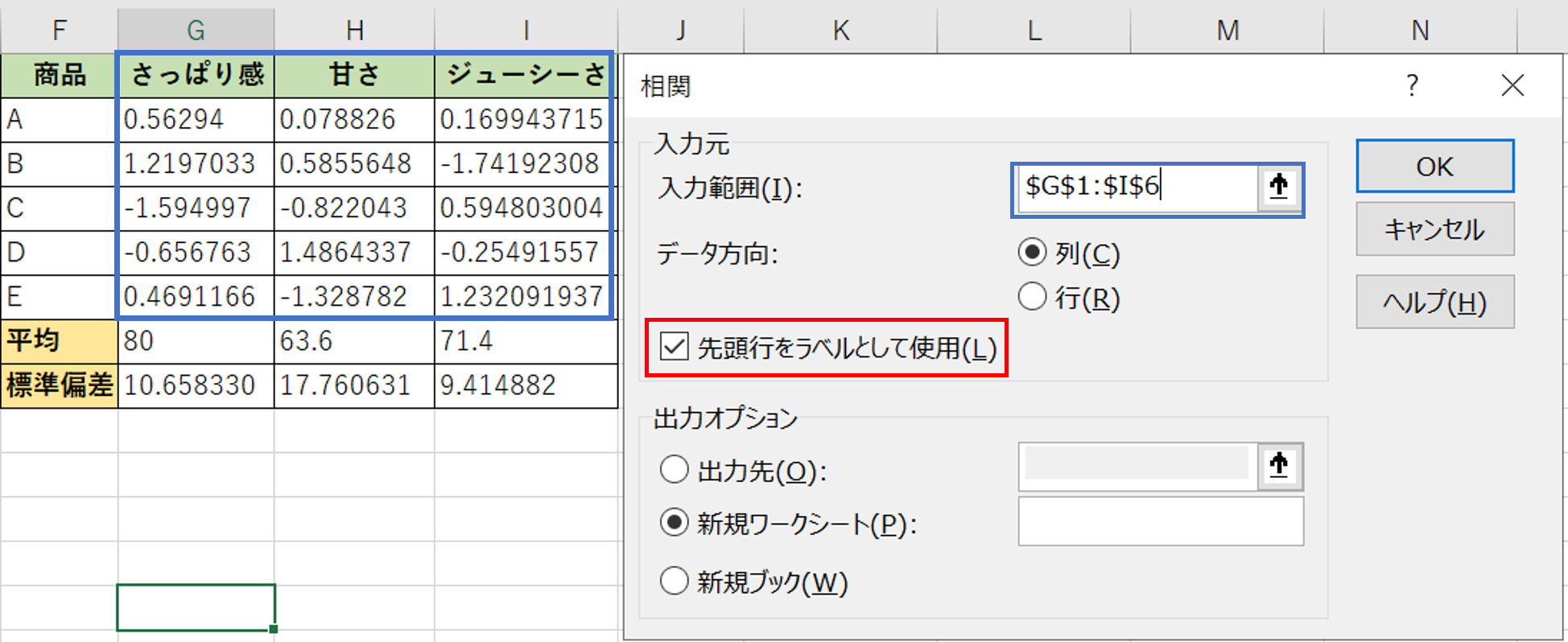
次に、入力範囲を選択するポップアップが出てくるので、青枠の部分を入力します。
その際、先頭行をラベルに使用したほうが良いです。
分析結果は以下になりました。

作業の半分くらいまで終わりました!
あとは、以下の3つの作業になります。
相関係数の固有ベクトル算出 → 主成分得点算出 → グラフ化
では、固有ベクトルを計算してみましょう!と言いたいところなのですが・・
計算式が複雑なうえ、Excelのツールでは求められないようなので、
固有ベクトルの計算サイトを利用させていただきました!
キーワード
結果は以下になります。

結果を見ると、第○主成分と記載がありますね。
こちらはなんでしょうか?
序盤でお見せした以下の図を見るとわかりやすいと思います。
こちらの矢印の軸が、第〇主成分にあたります。
・・・ですが、軸が2本しかないですね。
主成分分析の目的を思い出してみましょう!
たくさんのデータから情報を縮小し指標化することですね。
そのため、3つの主成分から2つに縮小させる必要があるのです。
それでは、いよいよ主成分得点の計算です!
以下の表を使用します。
・基準化後の表
・固有ベクトルの表
第1主成分の商品Aの計算をしてみましょう。
計算式が長ったらしいですが、Excelのスクショと併せて確認すれば分かりやすいと思います。
さっぱり感の固有ベクトル × 商品Aのさっぱり感 + 甘さの固有ベクトル × 商品Aの甘さ + ジューシーさの固有ベクトル × 商品Aのジューシーさ
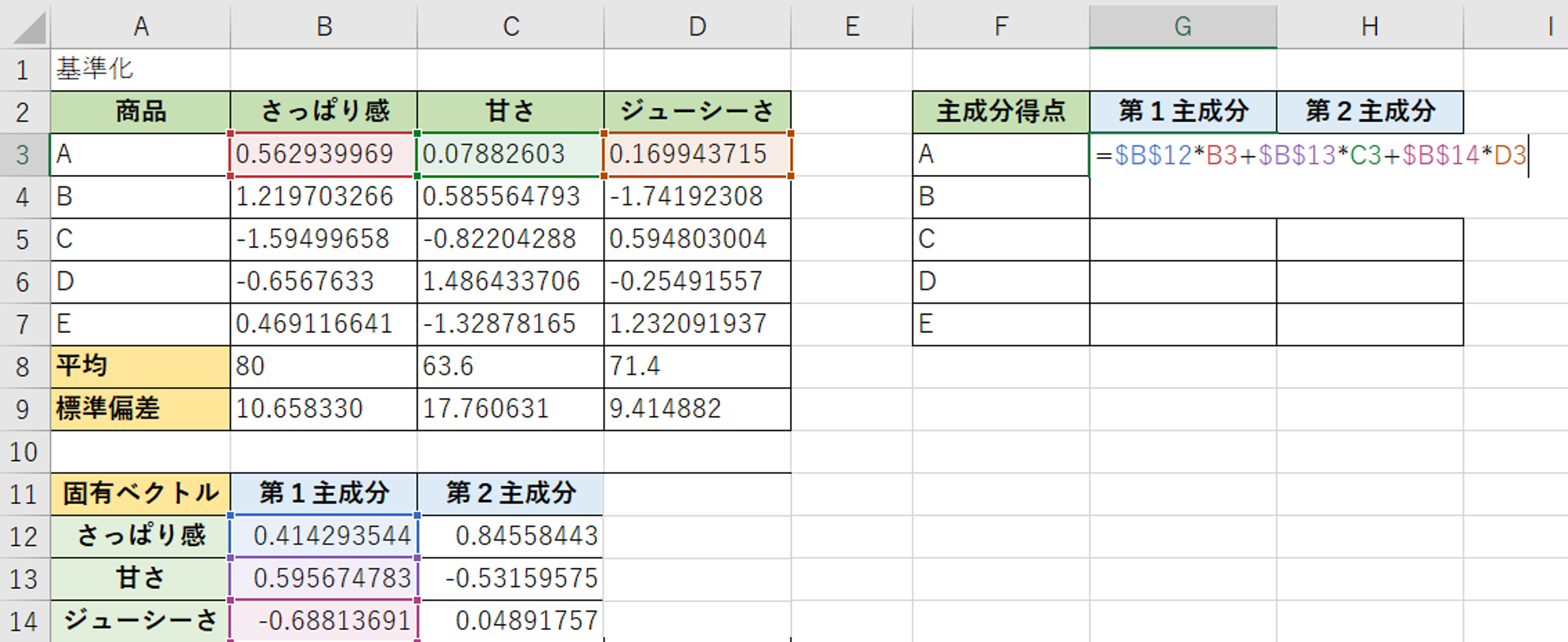
簡単に言えば、ベクトルと基準化した値をかけたら、すべて足していけばよいですね。
この調子で全て埋めていきます。
第2主成分まで算出した結果が以下になります。

この表を基に、ポジショニングマップを作ってみましょう!
Excelで簡単に散布図を挿入することができるので、やってみました。
青いポイントがそれぞれどの商品なのかわかるよう追記しました。
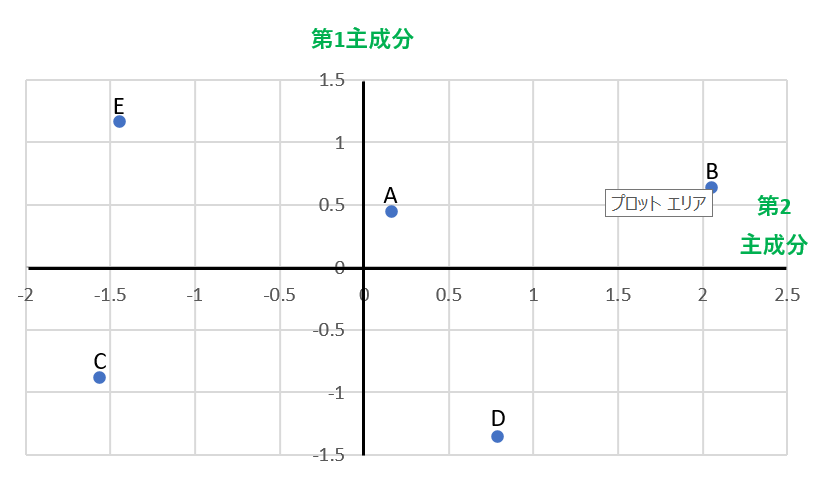
やっとここまで終わりましたね。
ですが、1つ疑問が残っています。
第1主成分・第2主成分の表していることは何でしょうか?
実は、この2つの名称を変える必要があります。
第1主成分は「総合」、第2主成分は任意の名称なんです。
今回は、「さっぱり感」「甘さ」「ジューシーさ」の3つなので、
第2主成分は「爽快感」にしたいと思います。
最終的に完成したポジショニングマップはこちらになります。
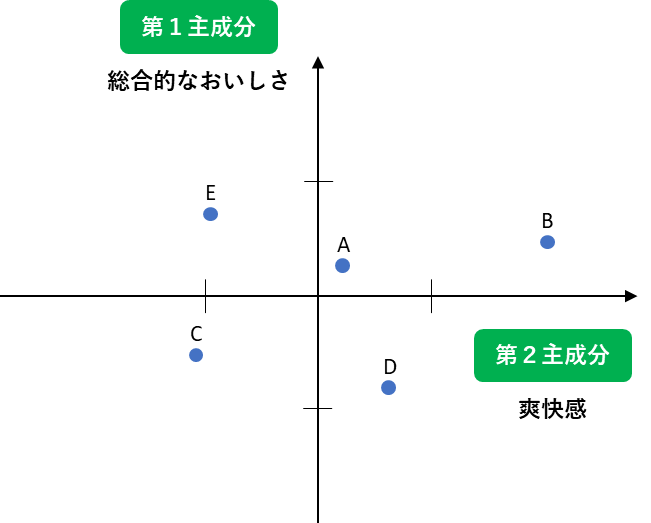
総論
今回、統計学に関しての最後のブログということで、1番難航していた主成分分析を紹介しました。
固有ベクトルの計算が調べても分からず時間を取られていたのですが、
最終的には、計算サイトを利用しました。
こちらの手法は、データをまとめ指標にするという目的から、
ほかの手法とはやり方が異なるのかな?と想像していましたが、過去のブログで紹介した、標準偏差などが出てきましたね。
ほかの手法と大きく異なると感じた点は、計算結果のみでは結論が分かりにくいというところです。
そのため、最後にポジショニングマップを作成した際は、目で見てわかりやすい結果になり、とてもスッキリしました。
以上で、統計学についてのブログは終了となりますが、
ほかにも多様な手法があるので、気になった方はぜひ調べてみてください!
次回は、Linux技術について紹介したいと思います。
<< 前の記事 次の記事 >>