

目次
いよいよ手法を調べます
こんにちは。AIシステム技術部 K山です。
前回は、統計学の目的とそれに対応する手法を整理しました。
情報を分析したいのかもしくは予測したいのかなど目的によって手法がちがうことや、同じ目的でもどれほどの粒度の結果を得たいのかによって手法が変わってくるということがわかりました。
目的ごとに手法をグルーピングしてみたので、今回の記事を読むまえにぜひ一読ください。→前回の記事はこちら

統計学の概要が理解できたから、早速「検定」の手法を調べてみてね。

「検定」とは?確率を使って、「立てた説は正しいといえるのか」を判断する作業になります。
前回の記事で、占い師が本物かどうかの検証を検定の例にあげたので、 今回もそれに当てはめて考えてみます。
【検定例】 自称占い師のゴットマザーが、5回連続で野球の勝敗結果を当てた。 本物の占い師なのか?
さて、この占い師は、本物でしょうか?もしくはペテン師でしょうか?
確立を使って考えてみます。
5回連続で結果が当たる確率を計算してみると、「1/243」です。

勝ち、負け、引き分けの3パターンが5試合あるため、分母で3を5回かけてます。
1/243を小数で表すと、0.00411522633だそうです。
予想はしていましたが、かなり低いですね・・・ こんなに低い確率のなかで、5回連続で結果を当てるなんて、 当てずっぽうではなく、占いの力で当てたのではないでしょうか!
ということで、占い師は本物といえるでしょう!
という結論になりましたが、本当にこれでよいのでしょうか?
確かに、確率は低いですが、当てずっぽうで当てた可能性も0ではありませんよね・・・ 適当に結果を予想してみたら、本当に当たった、というパターンかもしれません! それを無視して「占い師は本物だ」と主張するのは、なんだか主観で決めているように感じます。
ということで、仮説の採択基準を詳しく調べたところ、新しい用語が出てきました。
キーワード
一般的に5%で設定されることが多い。
t値・・・「比較するデータに意味がある差があるかどうか」を示す値。
p値・・・「得られたデータの希少性」を示す値。
有意水準よりp値が小さければそのデータは極めて起こりづらい。
有意水準の「有意」は、意味があるということです。統計学では、偶然に起こったとは認めがたいことを意味しています。
上記の説明を見る限り、p値がわかれば結果を得られる気がします。
有意がないということは、多少誤差があっても偶然であるとすることで、
有意があるということは、単なるズレではなく意味があるものとすることです。
有意があるのかないのかを判断するために、有意水準が必要になってくるため、
仮説同様、あらかじめ決めておく必要がありますね。
では、「占い師は本物なのか」を検定を使って調べるにはどのような手順を踏むのでしょうか?
①仮説をたてる ②有意水準を設定する ③t値を出す ④p値を出す ⑤有意水準とp値を比較する |
①の仮説では、2つの仮説を立てます。
キーワード
対立仮説・・・帰無仮説が棄却されたときに、採用される仮説。
※棄却・・・仮説を間違っていると判断すること。
帰無仮説は、棄却される前提で立てられる仮説であり、帰無仮説は正しくないことを証明するための検証を行います。
つまりは、帰無仮説には、主張したいこととは逆の説を立てます。
わかりやすくまとめると、以下の様に判断します。
有意水準 < p値 偶然ではある
気を付けていただきたいのが、
帰無仮説を棄却しないということは帰無仮説が正しいということではなく、結果を保留にするということになります。
×帰無仮説を棄却しない=帰無仮説が正しい
〇帰無仮説を棄却しない=どちらが正しいかわからない
保留にしたものは、また証拠を集めて検定すればよいですが、一度棄却したものは再考されないため、慎重に結論を出すことが大切です。
ここまでで説明した手順が基本的な流れになります。
検定について詳しく理解できたので、いよいよ手法に入ります!
t検定とは
検定を行う際に使用する手法の一つであり、1群のデータを使って検定する、もしくは2群のデータ同士を比較するときに使います。
2群のデータを比較する場合は、母集団から抽出した標本の平均に差があるかどうかを比較し、1群の場合は、固定値とそれぞれのデータを比較するやり方になります。
例えば、商品に500キロカロリーと記載があるが本当にそうなのか検定したところ、実際は違った。ここでは固定値が500キロカロリーで、データが実際のカロリーのことですね。
さらに、2群のデータ同士を比較する場合も、「対応のあるデータ」と「対応のないデータ」のどちらかによっても計算方法が少し変わってくるそうです。
対応がある・・・同じ人やモノで2回計測したデータの差を評価する場合
例)A組の2回分のテスト結果
対応のない・・・違う人やモノで計測したデータの比較を評価する場合
例)A組とB組のテスト結果
Excelを使って検定ができるそうなので、計算式を使っての検定と併せてそちらもやってみます!
t検定の手順
t検定とは、t値を利用する検定です。
t値を出すには、t分布を用います。
t分布とは、母平均が不明の場合に、母平均を推定する確率分布のことらしいです。
先ほどのt検定の説明文にて、
「母集団から抽出した標本の平均に差があるかどうかを調べます。」と記述しました。
母平均を推定するために、標本の平均を求める。
なるほど・・・つまり、標本の平均=母平均で、標本の平均に差があるなら母平均にも差があると考えるやり方なんですね。
ですが、p値はいつ使うのでしょうか?
p値がわかれば簡単なのに、t値を使うのはなんででしょうか?
調べたところ、t値が出ればp値もわかるそうです。
p値を調べるために、t値をまず計算するんですね!
t値の計算式は以下です。
t=(標本平均-母平均)÷(標本に基づく標準偏差÷標本数の平方根)
1つ1つ計算していったら、時間がかかりそうですね・・・
しかも、標準偏差という新しい用語が出てきました。
キーワード
標準偏差の求め方は以下です。

これはまた・・・難しそうな計算ですね。
t値にたどりつくまでに、かなり時間がかかりそうです。
キーワード
新たにでてきた「分散」というのは2乗の値と標準偏差が等しいようですね。
用語の意味が標準偏差と似ていますが、どう違うのでしょうか?
標準偏差と分散はどちらもほとんど同じのようです。
ただ、分散はルートで表していて少々わかりにくいため、形を変え標準偏差にすることもあるそうです。
あまり理由は気にしなくとも問題なさそうなので、「標準偏差=√分散」と覚えておきます。
とはいえ、√分散を求める式が複雑でしたね・・・
それに、p値の計算式を調べても出てきませんでした。
これでは、せっかく標準偏差を求めてからt値まで出しても、先に進めないです・・・
仕方ないので、Excelを使ってみましょう。
p値を自動で出してくれるそうなので、問題なさそうです。
まず、Excelで検定ができるように設定をします。
ファイル>オプション>アドインで、
分析ツールの設定をします。
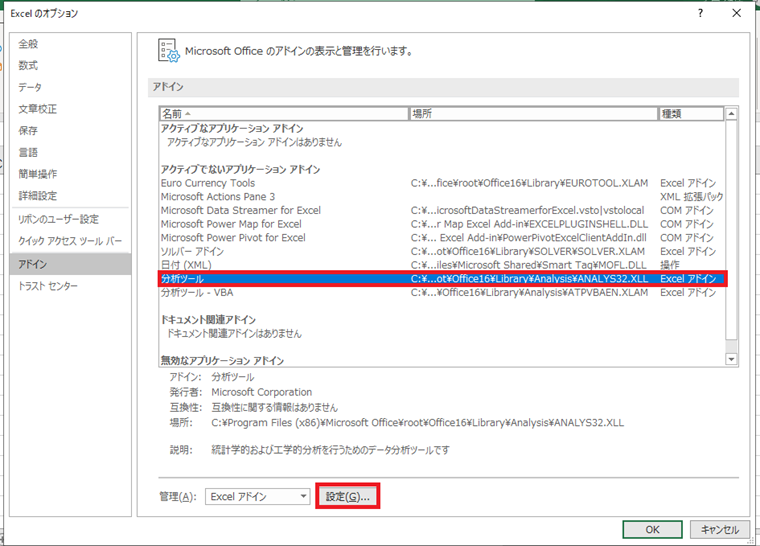
すると、以下のポップアップが出てくるので、「分析ツール」にチェックを入れ、
OKを押下すれば、検定ができるようになります。

それでは、t検定やってみましょう。
まずは、「対応のあるデータ」から検定していきます。
以下の表は、同じ人物に、朝夜1回ずつ検温していただいた結果のデータです。
こちらを使って検定します。

まず、仮説を立てます。
ここでは、予想している結果とは反対の結果を仮説として立てます。
仮説:朝と夜の体温の変化は、同じ傾向にある
次に、有意水準を設定します。
有意水準:5%
仮説と有意水準を決めたところで、仮説が正しいのかを見極めるために計算をします。
以下画面の「データ分析」を押下します。

すると、以下のポップアップが出てくるので、
「t検定:一対の標本による平均の検定」を選択します。

表のデータを入力します。

変数1の入力範囲:体温(朝)のデータ範囲
変数2の入力範囲:体温(夜)のデータ範囲
仮説平均との差異:2つのデータの意味は同じという0を入力
a(A):有意水準(5%)
計算結果が出ました。
注目すべき点は、「P(T<=t)両側」の値です。

「P(T<=t)両側」の値が、有意水準である0.05(5%)より下回っていると、有意ありとなります。
今回は上回っているので、有意なしとなり帰無仮説は棄却されません。
つまり、多少の差は偶然起こったものであり、体温の変化は同じ傾向になっているという結論になります。
次に「対応がないデータ」を使ってやってみます
こちらは、異なる人物からとったデータである必要があるため、AグループとBグループに分けのそれぞれのお小遣いを表にしました。
有意ありにするために、AグループとBグループの差を大きくしてみました。
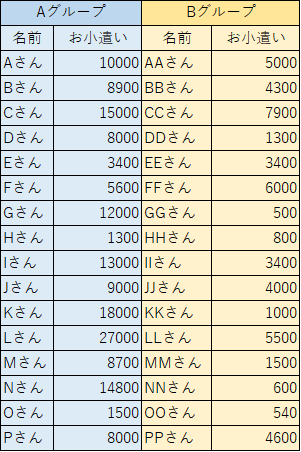
仮説:AとBでは有意差はない
有意水準:5%
「対応しているデータ」の場合は、「一対に標本による平均の検定」を選びましたが、
今回は、「等分散を家庭した2標本による検定」を選択してください。
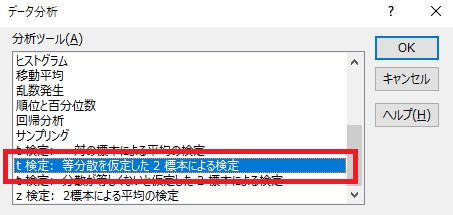
この後のデータ入力は先ほどと同様です。
結果は以下になります。

今回は、p値が有意水準(0.05)を下回りましたね。
ということで、はじめに立てた仮説は棄却され、有意ありという結論になります。
ここまでが、T検定の手順になります。
なんとかt検定ができました!

じゃあ、このまま他の手法もやってみよう。

(t検定だけでも覚えることが多いのに、一気にやるのは厳しいなぁ)
また、手法を実際に使ってみる段階で、また新たに用語や計算式がでてきてボリュームが多かったです。
ここでさらに別の手法を調べるとなると、理解が追い付かないと思うので、次回に回したいと思います。
総論
今回は、検定の手法である「t検定」を実際に試してみました。
確率を使うだけの手法と思いきや、「有意水準」「標準偏差」などの新しい用語が多く複雑でした。
しっかり内容を理解するためにも、別の手法については次回のブログで説明することにしました。
t値の計算式はとても複雑でしたし、p値の出し方が調べてもわからなかったのでどうなるかと思いましたが、Excelのツールを使い自動で値を割り出すことができましたね。
Excelに統計学の分析機能があったのは驚きでしたし、初めて統計を勉強する方でも取り組みやすいと感じました。
次回は、検定の後編になります。以下の手法を紹介します。
・分散分析
・多重比較法