

目次
始めに
こんにちは。AIシステム技術部 K山です。
前回は、推定の手法を紹介しました。
もともとは、「点推定」のみを紹介する予定でしたが、
調べたところ「区間推定」という手法のほうが、結果の信頼度が高いことに気がついたため、「点推定」「区間推定」の両方を紹介しました。
前回のおさらい
| ・点推定では、母集団の平均 = 抽出したデータの平均になるだろうと推測する ・区間推定では、100回抽出したうちの95回含まれるである母集団の平均区間を推測する ・点推定は抽出するデータによって平均が異なる場合があるため信頼性に欠ける 反対に、区間推定では標準誤差と95%信頼区間を使用することにより、ほとんど正確な推測ができる |
今回は、題名の通り「重回帰分析」をやりたいと思います。
「重回帰分析」とは、予測をする際に利用される手法です。
そもそも統計での「予測」とは
予測と推定は、なんだか同じような意味合いな気がしますよね。
ですが少し異なります。
推定は、今あるデータの一部を抽出して全体の特徴を推測することで、
予測は、今あるデータからまだ起こっていない事象を予測することです。
利用例として、わかりやすいものでいうと天気予報や、売上予測などがあります。
天気予報のほうが、生活に身近なものだと思います。
予報では、天気・風・降水確率・気温・・・などの情報がわかりますよね。
実は、とても膨大な過去データから、同じようなパターンを読み取り、
「温度や湿度がこのぐらいであれば天気はこう変化する」などの様に予測しています。
降水確率に関しては「%」で表示されますよね。
「雨が降る確率なのかな」と考えがちですがそうではなく、
1mm以上の雨が100回 中 〇〇(%)回ある、ということなんです!
例えば、降水確率10%だった場合、100回 中 10回は雨が降るので、「10%だから降らない」
とも限らないのです。
このように、統計学の予測は、身近なものでも利用されています。
重回帰分析とは
「重回帰分析」の「回帰分析」とは、
結果を示す数値(目的変数)とその要因となる数値(説明変数)の関係を調べる手法です。
キーワード
説明変数・・・目的変数の要因となるもの。
説明変数が複数の場合は、「重回帰分析」といい、1つの場合は、「単回帰分析」という手法になります。
目的変数は結果のことなので理解できますが、
説明変数に関しては、このキーワード説明のみでは分かりにくいですね・・・
例えば、
アイス屋さんの売上予想をしたい場合、
まずどんな要因が売上を左右しているのか?という点を考えます。
商品の種類・価格だけでなく、
「人通りの少ない場所に店があることにより客の入りが悪い」という立地的な問題や、
「冬は季節外れなので客があまり来ない」などの気温も、売上に関係がありそうですよね。
この販売量・種類・立地・気温が説明変数(要因)にあたるのです。
重回帰分析では、これらの要因と結果との関係性が分かれば、
起こりうる先の結果を予測することができるのです。
では、これらを踏まえたうえで、実際に重回帰分析をやってみましょう。
重回帰分析の手順
今回は、県内のラーメン店の売上予想をすると仮定しましょう。
まず初めに、影響を及ぼしそうな要因を考えます。
下記の点ぐらいでしょうか。
・最寄駅からの徒歩時間
・座席数
・期間限定商品の有無
・ライバル店との距離
・都市の人口
・道の通行量
ではここから、説明変数を絞っていきます。
なぜ絞る必要があるのでしょうか?
説明変数が多いと・・・
・その分データが必要になる
・わかりにくい
という点があるためです。
先ほど挙げた説明変数をすべて使用することになったら、
それらすべてのデータを集めなくていけません。
また、実際に集めて分析したとして、
複数の説明変数が結果に影響していたら、
「売上を伸ばすには、人が多いところ且つ最寄り駅から近いところに移転して、店も大きくして客がたくさん入れるようにしましょう、またライバル店が多いところも避け、期間限定品も考案して・・・」
ということになり結局なにが重要なのかが分かりにくいので、絞って簡潔にした方が良いですよね。
ということで、説明変数は以下になります。

これら3つの説明変数と目的変数の関係性を表す式として、以下のものがあるそうです。
年間の売上 = A₁+ A₂ × 最寄駅からの徒歩時間 + A₃ × 座席 + A₄ × 期間限定商品の有無
A₁ 、A₂などの係数が分かれば、
・どの説明変数が結果に影響を与えているのか?
・座席を増やすとどのぐらい売上を増やすことができるのか?
などについても分かるのです!
それでは、Excelを使って係数を調べることができるので、やってみましょう!
サンプルデータは以下になります。

まず、以下のように、「データ」タブの「データ分析」を選択します。

そこでポップアップが出てくるので、
「回帰分析」を選択します。
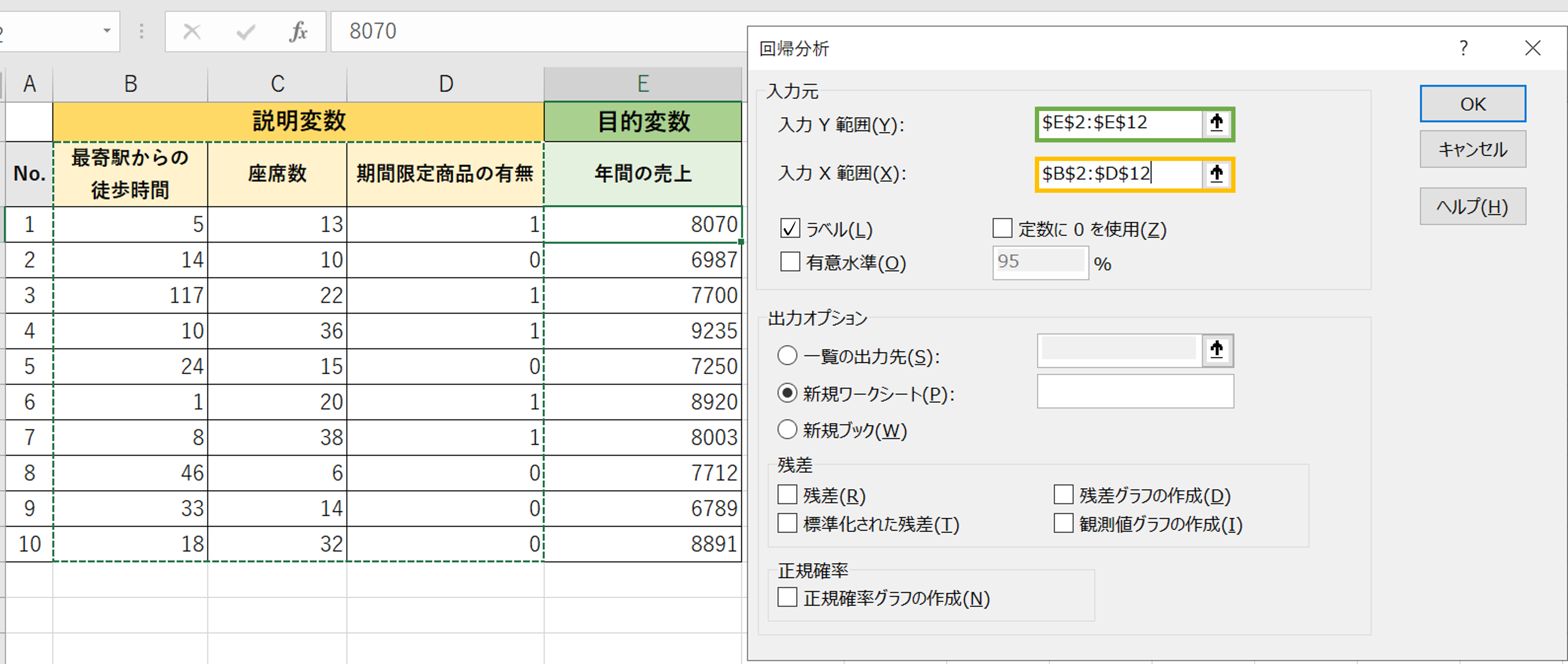
そしたら、入力範囲を選択します。
それぞれ、Yが目的変数、Xが説明変数にあたります。
分析した結果が以下になります。

ということで係数が出てきましたね!
先ほどの式を埋めてみましょう。
年間の売上 = A₁+ A₂ × 最寄駅からの徒歩時間 + A₃ × 座席 + A₄ × 期間限定商品の有無
↓ ↓ ↓
年間の売上 = 7162 -6 × 最寄駅からの徒歩時間 + 34 × 座席 + 515 × 期間限定商品の有無
上記の式を使えば、売り上げの予測ができるということですね!
また、お気づきかと思いますが、
最寄駅からの徒歩時間の係数のみ、-(マイナス)がついていますね。
ついているものとそうでないものは、どういった違いがあるのでしょうか?
-(マイナス)がついていないものに関しては、
値が大きくなると、売り上げも上がるということを表しています。
反対に、-(マイナス)がついているものについては、
値が大きくなるほど、売上が下がる、ということです。
つまり、徒歩時間がかかる場所にある店ほど、売上が低いのです!
ではどの説明変数が一番影響しているのか、についてですが、
係数が0から離れていればいるほど、影響していると解釈します。
この中でしたら、「期間限定の商品の有無」が一番0から離れているので、影響が強いと考えられます。
総論
今回、「予測」の手法である「重回帰分析」しました。
初めは、推測と予測の違いについて調べたところ、
推測では、すでに起こっている事象において、一部のデータを使い全体の特徴を捉え、
予測では、まだ起こっていない事象において、先のデータを予測することを理解しました。
さらに重回帰分析では、予測に加え、
予測結果に関係しているもの(説明変数)はなんなのか、ということも分析しましたね。
まず関係がありそうな要因をいくつか挙げ、そこから絞って、重回帰分析を行いました。
分析後に分かる係数の値が、
正の数の場合:値が大きくなれば、結果の値も大きくなる
負の数の場合:値が大きくなれば、結果の値は小さくなる
ということが分かるとともに、
値が0から離れれば離れるほど、予測結果への影響が強い、ということも分かりました。
マーケティングでのリサーチでは、重回帰分析はよく利用されるそうです。
今回実施してみましたが、Excelなどツールを利用すれば簡単にできますし、
分析目的や分析結果が分かりやすいので、初心者の方は取り組みやすい手法であると感じました。
次回は、以前苦戦した「要約」の手法をもう一度取り組みたいと思います。
・主成分分析