

目次
t検定以外の手法
こんにちは。AIシステム技術部 K山です。
前回は、検定の主な例と手法の1つである「t検定」の手順を説明しました。
前回のおさらい
| ・検定では、ただ単に「確率が低いから」「偶然では起こりにくそうだから」という主観で結果を決めるのではなく、水準を設けることで公平な結論が下される ・検定前にたてた仮説が正しくないからといって仮説とは反対の説を採択すると、その後の再検定は行われないことがほとんどである →結論を急ぐのではなく「2つの仮説のうちどちらが正しいかわからない」という結論にするのも1つの手段である |
前回のブログにて、検定の詳しい説明を記載しています。
今回の記事を読むまえにぜひ一読ください。
→第3回 統計学 検定(前編)「検定とは」
分散分析と多重比較法
●分散分析
3群以上のデータがある場合に使われ、母平均の差を調べる検定です。
t検定は、1群のデータを使って検定する、もしくは2群のデータ同士を比較するときに使うので少し似ていますね。
ですが、分散分析には一元配置と多元配置という2つのパターンがあり、それぞれやり方が異なります。
一元と多元では何が違うのでしょうか?
例えば以下の様に、短距離走の平均をクラスごとに割り出したとします。
一元配置の場合は「クラス」という1つの分類で分かれてます。

多元配置では、「クラス」と「性別」という2つの分類で分かれるようなイメージです。
これら分類が3つ~4つになる場合もあり、2つ以上のものはすべて2元配置といいます。
(多元配置ということもあるようです。)

●多重比較法
分散分析の実施後、さらに詳しく調べたいときに使う手法のようです。
検定を行っても「全体的に差がある」ということしかわかりませんが、多重比較法を使えば具体的にどこに差があるのかがわかります。
t検定と分散分析は似ているように感じますが、多重比較法は検定の応用な気がします。
では、それぞれの違いがわかったところで、いよいよ手法を使ってみたいと思います。
今回も、Excelを使っての検定手順を併せて説明します!
分散分析の手順
t検定ではt値を使用しましたが、分散分析では、f値を使うようです。
キーワード
大きければ大きいほど、分散に差がないといえる。
t検定ではt値を出してからp値を求めていましたが、分散分析ではf値をだしてからp値を求めます。
f値の計算式は、「各因子の平均平方÷残差の平均平方」です。
なんだかt検定よりは自力でできそうですね!
平均平方とは、母集団の分散を予想したものらしいです。
計算式は「平方和÷自由度」です。
また新しい用語が出てきてしまいましたね・・・
「平方和」とは、各データと平均の差のことで、すべての偏差(平均値との差)を2乗して足せば値が出るそうです。
(偏差1の2乗)+(偏差2の2乗)+(偏差3の2乗)・・・
ということですね。
そして「自由度」とは、自由に決めることができる値の数のことです。
例えば、足し算の答えが「4」になるような組み合わせを考え、以下の式になった場合、
1+2+1=4
1つ目と2つ目は自由に決められますが、3つ目の数字は、強制的に「1」になりますよね。
2つ目の数字までしか自由に決められないので、上部の式の自由度は「2」になります。
求め方は、「n(データの数)-1」です。今回は、nは3ですね。
いくつか初めての用語がでてきたので、それぞれの説明をまとめてみました。
キーワード
求め方:平方和÷自由度
平方和・・・各データと平均の差のこと
求め方:すべての偏差を2乗して足す
偏差・・・平均値との差
求め方:平均-データの値
自由度・・・自由に決めることができる値の数
求め方:n-1
意味と求め方がわかったので、f値が出せそうです。
下記の順に計算していきましょう!
1.各因子
①平方和
②自由度(それぞれのデータ群がもつデータ数-1)
③平均平方
2.全因子(残差)
①平方和(各因子の平均平方の和)
②自由度(すべてのデータ-群数)=(すべてのデータ-1)+(すべてのデータ-1)・・・
③平均平方
3.全体
①全体の平均平方の和
②自由度(すべてのデータ数-1)
4.f値
①各因子の平均平方/残差の平均平方
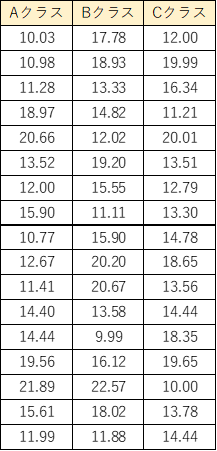
サンプルで、A,B,Cクラスの100m走の記録データを作りました。
こちらを使って、計算式でf値を求めます。
その前に・・・仮説と有意水準を決めましょう!
3つのクラス間では、あまり差がないように感じます。
仮説は、期待している結果とは逆に設定するため、以下にします。
仮説:AとBとCでは有意差がある。
有意水準:5%
では、先ほどの計算手順にそって値を割り出していきます。
まずは、各因子の平方和まで出しました。
キーワード
平方和:偏差の2乗をすべて足したもの
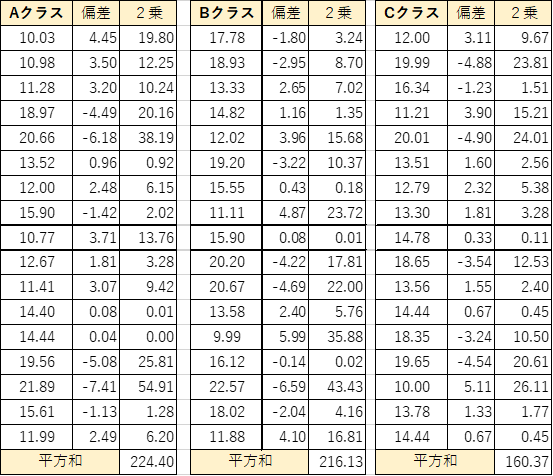
f値までだせました!
p値の計算式は分からなかったので、Excelの関数を使います・・・
F.DIST.RT(f値,群間の自由度,群内の自由度)

関数を実行した結果、p値が有位水準より高いので、有意差はありません。

p値まで、自力で計算してみましたが、結構時間かかりますね。
t検定と同様に、Excelのツールでp値を自動で出してくれるようなので、そちらも試してみましょう。
「分散分析:一元配置」選択します。
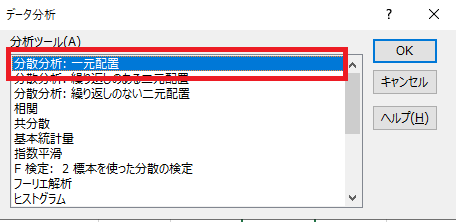
入力範囲は、AクラスからCクラスのデータすべてを指定します。

自動分析の結果はこちらです。
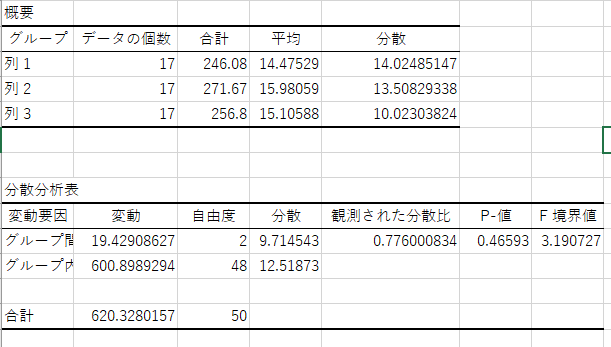
先ほど、一つ一つ計算していった際に小数第二までで計算したので多少誤差はありますが、近しい結果になっていますね。
p値が有位水準より高いので、今回は「有意差がない」という結論のため、
仮説は正しくないということになります。
それでは、2元配置のやり方も試してみましょう。
2元配置の場合は、以下赤枠の2種類のやり方があるようです。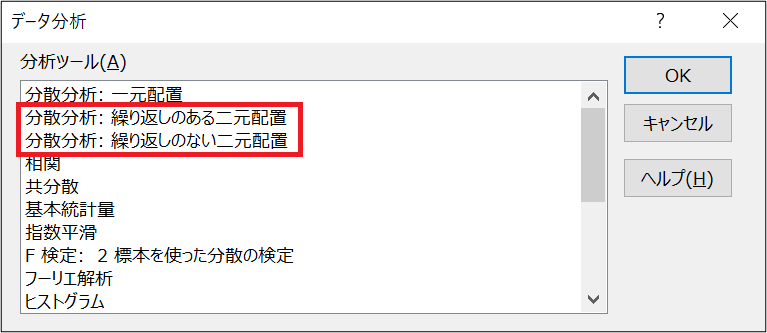
「繰り返しのある二次元配置」と「繰り返しのない二元配置」は、どんな違いがあるのでしょうか。
それは簡単です。
同じサンプルから、複数回記録をとっているのか、とっていないか、の違いです。
例えば、学生Aさんが学校のテストを受けました。
テストを受けた回数が1回だけなら「繰り返しがない」、
赤点をとって追試を受けることになれば、回数は2回以上なので「繰り返しがある」といえます。
今回は、「繰り返しのある」2元配置とします。
晴れの日、雨の日、雪の日に計測した、生徒6人の100m走の記録データを作りました。
上記のデータを使って分析するのですが・・・
1元配置と同様に、入力範囲を設定したところエラーのようなものがでました。
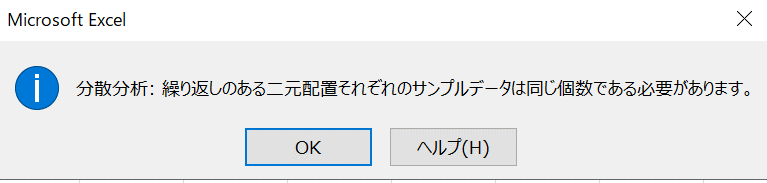
2元配置の場合は、A列・1行目に記載の「データ名」も含める必要があるみたいです。
以下の様に設定します。
「1標本あたりの行数」は、で同じ方からデータをとった回数ですね。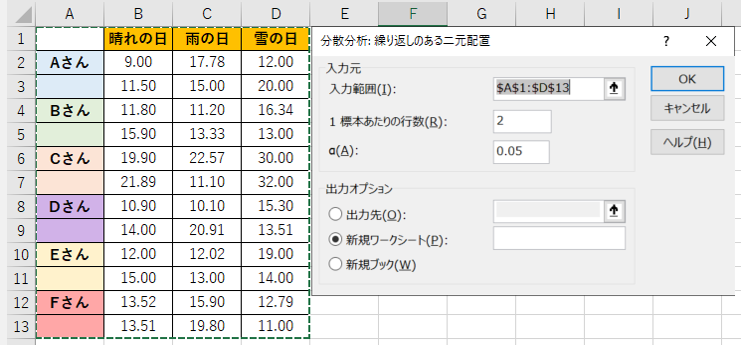
分析をした結果はこちらです。
このように、AさんからFさんのそれぞれの平均・分散も別表で出力されます。
今回でいうと、「標本」が生徒で、「列」が天気にあたります。
「交互作用」とは、標本と列が相互に影響を及ぼしているかどうかを見るものなのですが、
「P-値」を見ると、標本のみが5%未満なので生徒間でのみ有意差があるということがわかります。
多重比較法の手順
多重比較法とは、分散分析のあとに使う手法の総称で、検定の結果「有意あり」となった場合に実施します。
調べたところ、「多重比較法」とは、手法の名前ではなく、複数の手法の総称のようです!
代表的な手法は、以下になります。
| 手法 | 概要 |
| Bonferroni(ボンフェローニ)の方法 | 検定で得られたp値を補正する手法。比較するデータ群によって有意水準を調整する。 |
| Tukey(テューキー)の方法 | 全体の平均と、その他のすべての平均を比較する手法。 |
| holm(ホルム)の方法 | 検定で得られたp値を補正する手法。データ群の組み合わせの数をかけていき、書ける数値を小さくしながら補正する。 |
Bonferroniの手法は、難位度が低いそうなので、4つの手法から抜粋して紹介したいと思います。
先ほどの分散分析の結果は、「有意差がない」ため、有意差がありそうなデータに書き換えました。
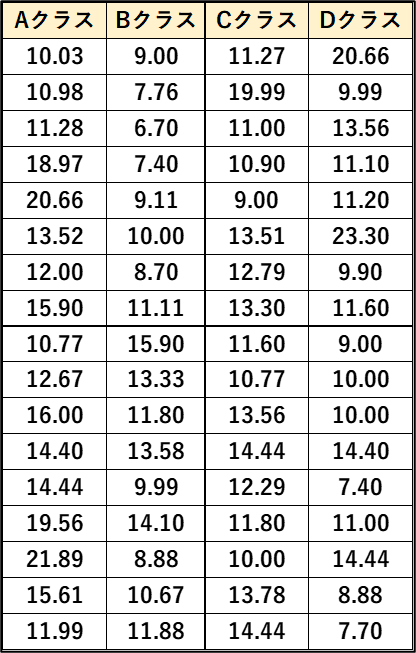
こちらを使って早速やってみましょう!
まず、「AとB」「AとC」のように、データ群の組み合わせをつくっていきます。

それぞれの組み合わせにした場合の、p値入力します。
分散分析の後に実施するので、分散分析のデータをそのまま利用するのかと思っていました!
しかも、2つのデータ群を比較したときのp値なので、ここでt検定をする必要がありますね!
(前回のブログで、Excelでのt検定の手順を説明したため、今回は省略します)
→第3回 検定 t検定「t検定の手順」
それぞれのp値を出しました。

次は、p値と組み合わせ数(今回は4)をかけて、p値を補正します。

補正した値をみると、「AとB」を組み合わせた場合が0.05未満なので、
「AとB」に有意差があるという結論になります。
割り出したp値に組み合わせ数をかけるだけとは、Bonferroniの手法は簡単ですね!
・・・こんなに簡単であれば、すべてBonferroniの手法を使って多重比較すればいいのに、
なぜ、ほかにも手法が存在するのでしょうか?
調べてみると、Bonferroniの手法は検定の回数が多ければ多いほど、有意か有意でないかの基準が低くなるそうです!
やり方は簡単ですが、思わぬ落とし穴がありましたね・・・
ということは、すべての手法においてもそれぞれ基準が違うのではないでしょうか。
他の2つの手法もBonferroniの手法と比較してみましょう!
◆Holmの方法
Bonferroniの手法と似ており、こちらもp値を修正する手法です。
違いとしては、
組み合わせ数を-1していくところですね。
まず、p値が一番小さいものを選び、p値と組み合わせ数をかけます。
「AとB」のp値が一番小さいので、「0.0005*4」をします。
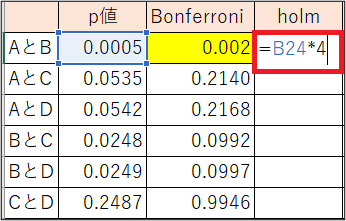
ここから、組み合わせ数を-1していきます。
2番目にp値が小さいのは、「BとC」なので、
「0.0248*3(組み合わせ数-1)」となります。

次に「BとC」も同じように計算をします。
すると、以下の様にほか3つの組み合わせは5%(有意水準)以上になっていることに気が付きます。
5%を超えた時点で中断となるそうなので、
以下の様に、「AとC」「AとD」「CとD」は補正されないという結果になります。
p値修正後、5%未満が「AとB」「BとD」の2つになりました。
Bonferroniの方法では、引っかからなかった「BとD」も有意差ありという判定になりましたね。
では続けて、Tukeyもやってみましょう。
◆Tukeyの方法
こちらは、前の2つの手法とはやり方が異なるようです。
これまでは、p値を修正した値で判断していましたが、今回は「平均」と「分散」を使います。
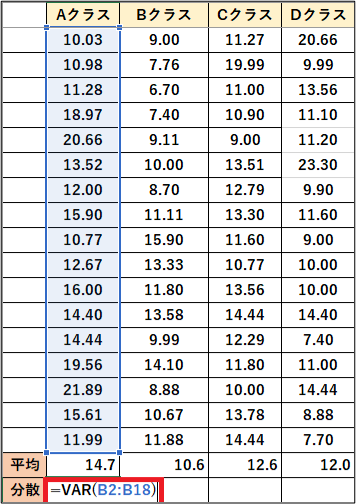
Excelでは、分散の値をだす関数(VAR)があるようなので利用しましょう。
クラスの全記録とその平均を出した表が以下になります。
ここからそれぞれの分散を出していきたいと思います。
関数(VAR)の後に、割り出す範囲を選択すると自動で分散が表示されます。
=VAR(セルのはじめ:セルの後ろ)
4つの分散を出し、その平均も割り出した結果が以下になります。
平均、分散、分散の平均の3つが揃って準備は完了です。

ここから、以下の計算をしていきます。
(平均-平均の絶対値)÷(分散の平均÷データ数の平方根)
日本語で書くとやはり分かりにくいですね・・・
Excelの関数を使って「AとB」の値を割り出すと、このようになります。
=ABS(B19–C19)/SQRT(E20/17)
※「17」は、1クラスのデータの数のことです。
残り組み合わせも計算してみました。

比べてみると、他の2つの手法で割り出した値と全然違います!
計算を間違えたのでしょうか・・・
実はそうではなく、最後に仕上げがあります。
ここで、「スチューデント化された表」というのを利用します。
こちらはネットで検索すると出てきますよ。
有意水準が1%の場合と5%の場合では、表が異なるので気を付けましょう。
今回は、データ群が4つ、データ数が17のため、赤枠の部分をみます。
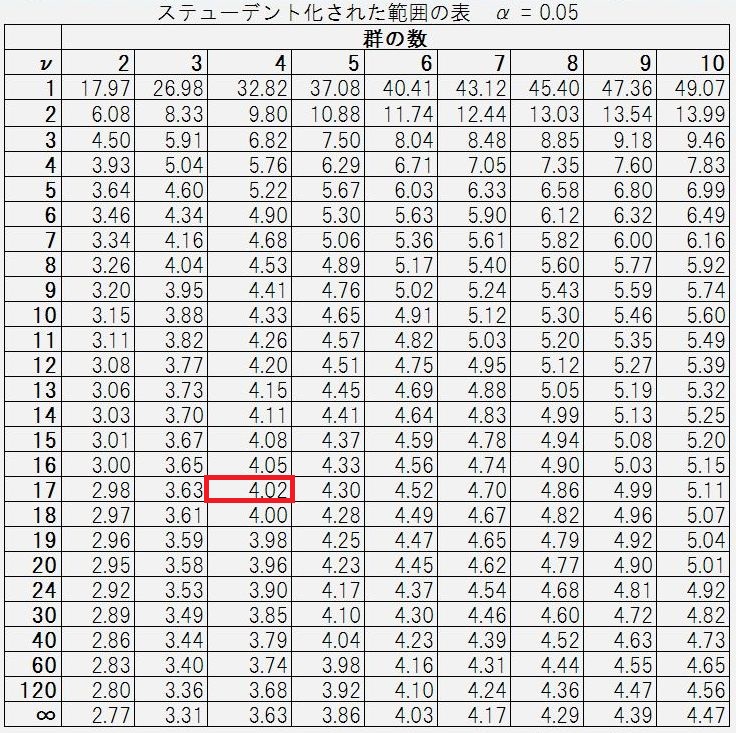
赤枠に書かれている「4.02」と先ほど分散を使って割り出した値を比較してみます。
つまり、これまで基準としていた5%と比較するのではなく、
「4.02」を基準とし、有意差があるか、そうでないかを判別します。
さらに、気を付けていただきたいのが、Tukeyの場合は、
基準より上回る場合に有意差ありということになります。
有意水準5%を基準にしていたときと逆なんです!
比較した結果以下の様になりました。
3つの手法を比べると、有意さがある組み合わせに違いがありますね。
Bonferroniの方法とHolmの方法の計算方法が似ていましたが、
その理由は、HolmはBonferroniの修正版だからだそうです。
Bonferroniは、データ群が4群以上になると、有意差の判断が甘くなります。
その点を修正したものがHolmということらしいです。
ということは、Bonferroniは3群比較にしか使えないということですね・・・
さらに、Tukeyはデータ群の数が5以上だと判断が甘くなるそうです。
それぞれの検出力を比較すると以下の通りですね。
Holm>Tukey>Bonferroni
総論
今回は、「検定」の手法である「分散分析」と「多重比較法」を実際に試してみました。
分散分析では、p値以外は何とか自力で値を出すことができましたが、
t検定と比べ新しい用語が多く、必要な値が多かったため、時間がかかりました・・・
Excelのツールを使っての分析がおすすめです。
多重比較法では、一つの手法のことを指しているということではなく、手法の総称のことが判明しました。
また、それぞれの手法は似ているものもあれば全くやり方が異なるものもあり、
比較するデータ群の数によって、向き不向きな手法が決まっているようです。
今回紹介した中では、Holmが一番検出力が高かったですね。
Bonferroniは一番優しい手法なので、統計初心者の方にはお勧めです。
次回は、「要約」の手法を紹介します。
・主成分分析